本文主要讨论这几个问题:
- 1.基本架构
- 2.适用场景
- 3.搭建步骤
- 4.小结
1. 基本架构
本文描述如何利用Apache Kafka(消息中间件),Apache Nifi(数据流转服务)两个组件,通过Nifi的可视化界面配置,快速构建异步持久化MongoDB架构。
Kafka和Nifi都是Apache组织下的顶级开源项目。其中Kafka来自LinkedIn,是一个高性能的分布式消息系统。Nifi来自NSA(美国国家安全局),是一个功能强大,提供可视化配置,支持分布式的数据流转服务(不仅仅是一个ETL工具)。
基本架构如下图所示:
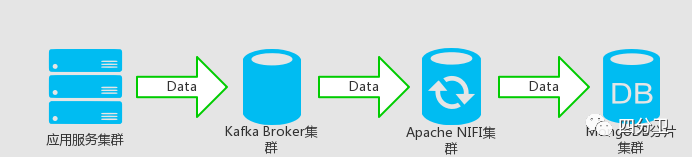
应用服务集群作为Kafka消息的producer,发送要保存或更新的数据到Kafka Broker集群。
通过Apache NIFI提供的可视化web界面,配置流程,消费Kafka对应Topic数据,将数据发送到MongoDB分片集群进行持久化。
高可用和伸缩:这里简要介绍下架构中各部分对高可用和可伸缩性的支持。MongoDB不必多说,通过副本集以及分片集群的部署架构,实现系统的高可用和分布式伸缩能力。其中Kafka通过日志分区(partition)实现消息数据分布式存储,以及对分区日志提供副本和容错机制实现高可用。Nifi也可以集群部署,多个节点可以并行的执行相同的工作流程(相同的consumer group id,保证每个节点并行处理的不同数据),集群中一个节点会选举为master,一些不能分布式处理的流程只会在master中执行。还有个节点会选举为coordinator,负责集群节点心跳以及集群节点加入退出管理等。nifi集群通过zookeeper的协调实现这两个角色的选举以及自动故障转移。
2. 适用场景
本文介绍的异步持久化架构主要适用如下一些场景:
1)业务允许异步持久化数据的情况(基本前提),比如爬虫抓取数据入库,日志存储等很多场景都适合异步持久化的模式。
2)数据多写:因为Kafka可以重复消费的特性,可以配置多个不同group id的消费者来实现多个不同的持久化或计算需求。比如可以在消费kafka消息持久化到MongoDB的同时,还可以消费这些数据持久化到HDFS或者通过Spark Streaming等流式计算框架进行实时计算分析。
3)流量削峰:有时业务会出现流量高峰,超出现有数据库集群的负载能力,通过消息中间件作为数据缓冲队列以及Apache Nifi提供的背压机制(Backpressure),异步持久化到MongoDB的方式,使得到达MongoDB的流量平稳,保证服务的稳定性。
4)易于配置和管理:Apache Nifi通过提供一系列可视化组件,可以很容易的配置数据流转流程,并且可以随时启动,暂停,修改流程。还可以通过自定义组件或脚本的方式,扩充流程和功能。
3. 搭建步骤
本文不介绍kafka集群,nifi集群,mongodb分片集群的搭建,官方都有相关说明文档。这里主要介绍通过Apache Nifi配置数据流转流程(从kafka到MongoDB)。
基本流程概览,如下图(图中方框代表基本的处理流程组件,箭头代表数据流向(可以配置多个箭头代表不同类型的数据,比如组件成功处理的数据,处理异常的数据等,具体类型根据输出组件有所不同),箭头中间的小方框可以理解为数据在组件间流动的队列。):
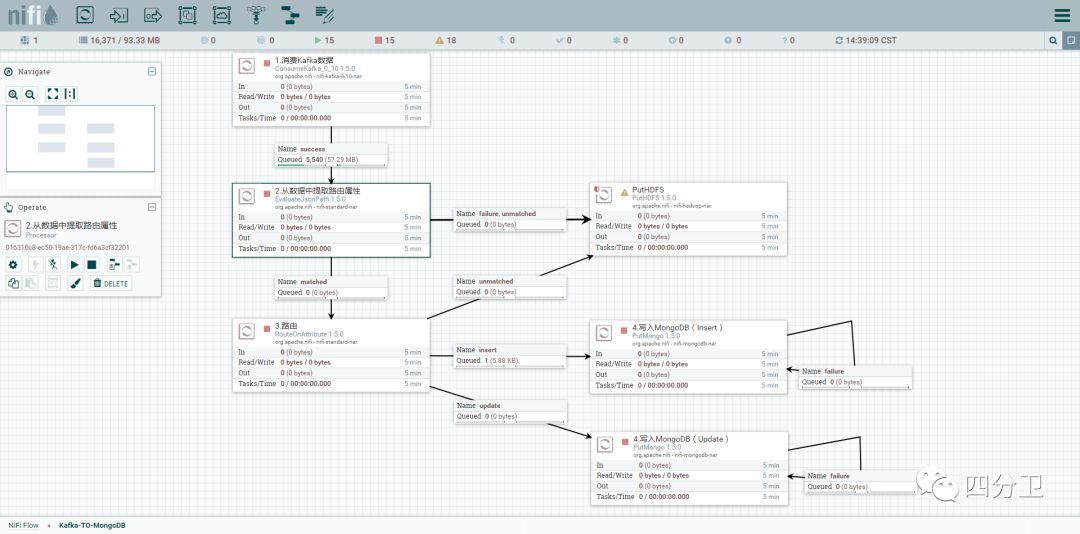
如图所示,主要分为4个流程:
1.消费kafka topic数据 -> 2.从数据中提取出入库及路由等信息 -> 3.根据属性值进行路由 -> 4.写入MongoDB
1)消费Kafka数据 (ConsumeKafka)
主要使用到的组件是ConsumeKafka_0_10组件,其中_0_10后缀代表组件适用的kafka版本,由于不同kafka版本在消息格式以及offset记录方式等存在差异无法兼容,在选择的时候一定要注意选择和部署的kafka集群服务匹配的版本。
还有一点需要特别注意的是,该组件会自动提交偏移量(”enable.auto.commit”, “true”),支持的消息投递语义是至少一次(at-least-once),所以在业务处理和入库上一定要注意保证操作的幂等性。
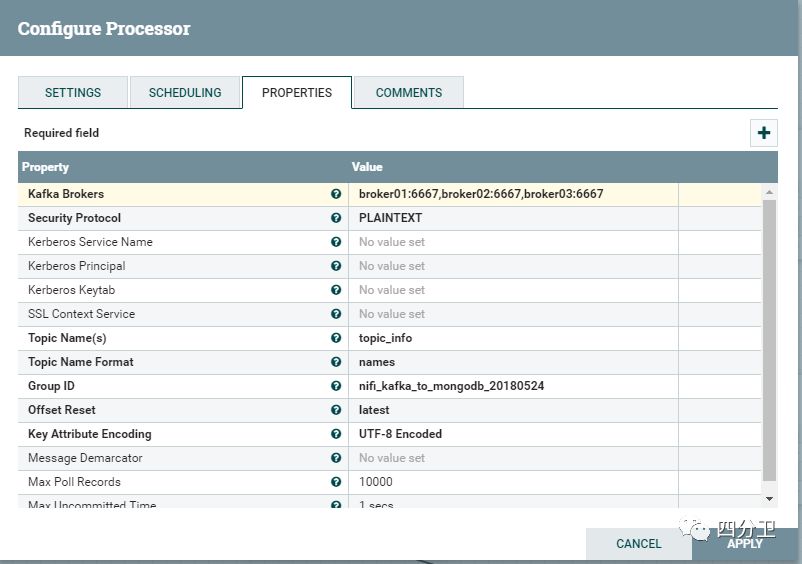
下面介绍下这个组件的几个组要配置项:
Kafka Brokers:配置Kafka broker集群地址
Topic Names:配置消费的主题(Topic)
Group ID:设置消费者所在消费组ID
Offset Reset:设置开始消费的偏移量位置,latest表示从最近的消息开始,earliest表示从kafka留存消息的最早位置开始
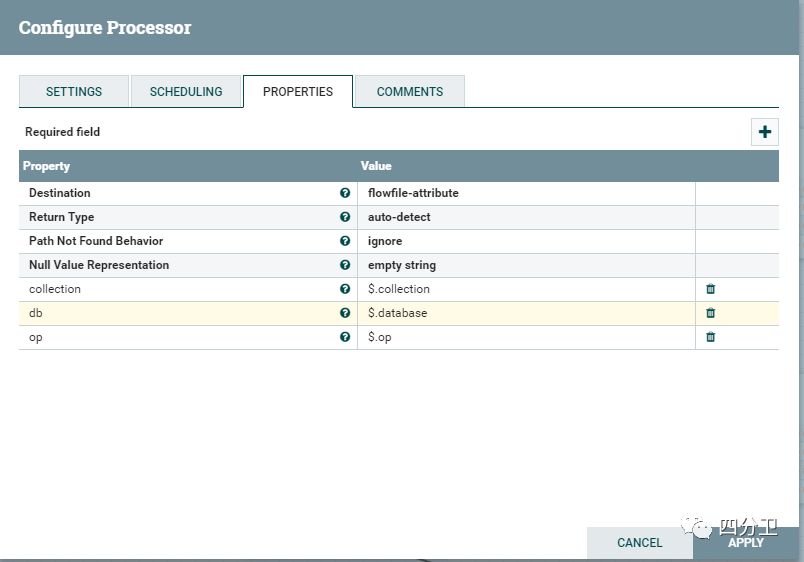
2)从数据中提取出入库及路由等信息 (EvaluateJsonPath)
为了让整个流程能够自动识别入库的一些信息,可以在业务写入到kafka的数据中记录一些元信息,比如这条数据要写入的Mongodb的库(database)和集合(collection)信息,或者区分是插入还是更新的信息。这里假设业务写到kafka的是json格式的数据,使用EvaluateJsonPath进行提取。
这里有关于性能的一个建议,适用于这里,也适用于我们任何程序写数据到mongodb的情形:慎用upsert(有就更新,没有就插入)操作,很多程序员为了省事,喜欢将所有的写入操作,都通过upsert的方式进行。但是基于性能考虑,如果能区分insert和update,建议直接使用insert和update,这样入库的效率会比不加区分的使用upsert好很多。
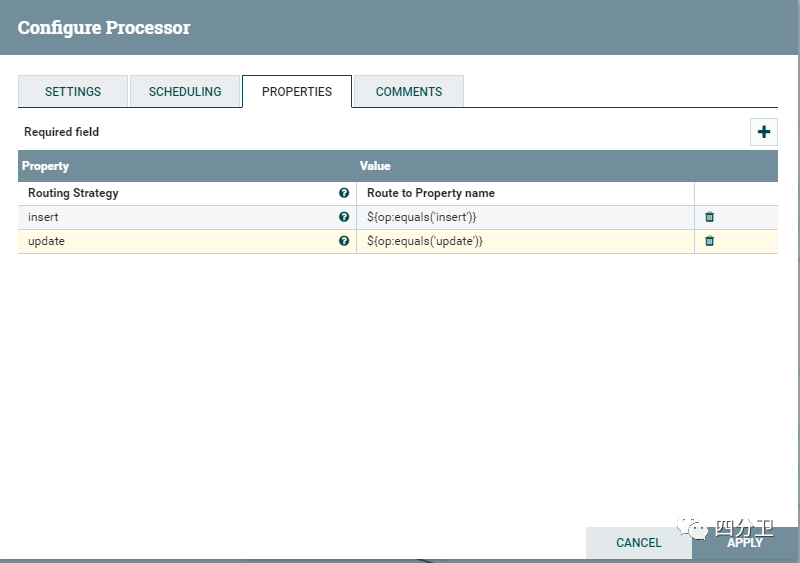
3)根据属性值进行路由(RouteOnAttribute)
通过RouteOnAttribute组件,根据上一步传递下来的op属性进行路由操作,将数据流根据操作拆分为insert和update
4)写入MongoDB (PutMongo)
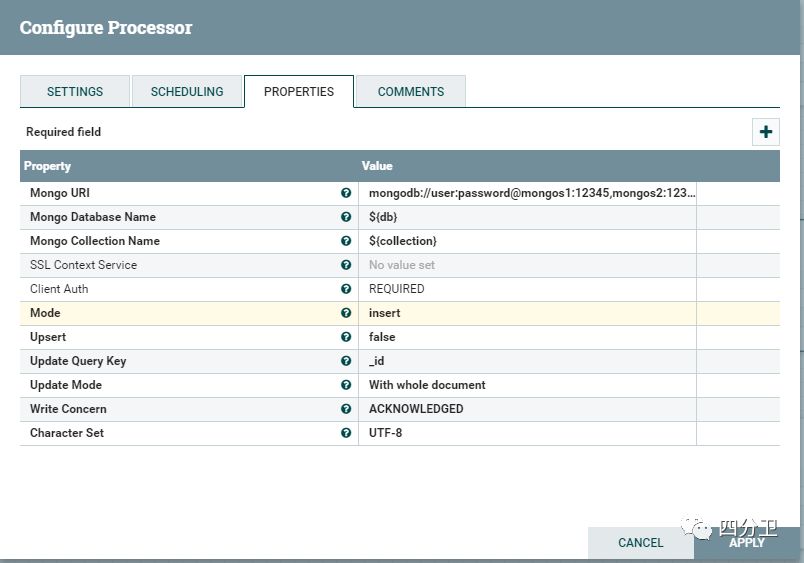
通过PutMongo组件实现数据的插入或更新。除了PutMongo组件,Nifi还提供了一个PutMongoRecord组件(用于bulk操作),这里主要介绍PutMongo。
下面介绍其中几个主要配置:
Mongo URI:mongos或mongod的连接串(uri)
Mongo Database Name:填写要插入的数据库名,可以直接填写数据库名,也可以使用表达式语言。NIFI提供了表达式语言的支持,这里${db}表示通过表达式语言取上一步传递下来的数据库属性信息。
Mongo Collection Name:${collection},同上,取传递下来的集合信息
Mode:表示写入操作方法。(对应MongoDB客户端驱动的insert, update等操作方法)
Upsert:表示是否设置upsert操作选项。
Update Query Key: 更新时匹配查询key
Update Mode:表示是全文档覆盖更新,还是可以通过使用操作符的方式只更新对应字段。
Write Concern:设置写关注。
4. 小结
整个流程配置就这么简单,熟练的话,一分钟就可以配置完成。NIFI提供给我们写程序外,另外一种简单直观又不失灵活的方式。
-390b9d6b3b0e4c6794304ad7f4bee697.png)